5 парсеров для facebook. парсинг аудитории для рекламы из групп, email, посты и id
Содержание:
- static defaultConf#
- Что такое парсер аудиторий?
- await this.parser.request(parser, preset, overrideParams, query)#
- await this.cookies.*#
- Zeus
- Зачем парсить группы в Фейсбуке крупнейшая социальная сеть в мире и одноимённая компания (Facebook Inc.), владеющая ею. Была основана 4 февраля 2004 года Марком Цукербергом и его соседями по комнате во время обучения в
- static parserOptions#
- Виды парсеров по технологии
- CleverTarget
- await this.sessionManager.*#
- Для групп + сбора email … и прочего
- С чего начать работу в Фейсбуке
- Как осуществляется парсинг?
- Какие существуют парсеры?
- static editableConf#
- Segmento Target
- Церебро Таргет
- async parse(set, results)#
static defaultConf#
static defaultConf ={
version’0.0.1′,
results{
flat
‘title’,’Title’,
,
arrays{
}
},
results_format»Title: $title\n»,
exampleKey’value’,
};
Скопировать
Конфигурация парсера по умолчанию, конфиг будет доступен в объекте класса через свойство , обязательными являются следующие поля:
-
— описывает в декларативном стиле результаты, которые может возвращать данный парсер
-
— задает формат результата по умолчанию
Все остальные поля являются опциональными, существует следующий список параметров, которые влияют на работу парсера:
| Название параметра | Тип | Описание(значение по умолнанию) |
|---|---|---|
| timeout | Максимальное время ожидания запроса в секундах() | |
| useproxy | Определяет использовать ли прокси() | |
| max_size | Максимальный размер файла результата() | |
| proxyretries | Количество попыток на каждый запрос, если запрос не удаётся выполнить за указанное число попыток то он считается неудачным и пропускается() | |
| requestdelay | Задержка между запросами в секундах() | |
| proxybannedcleanup | Время бана прокси в секундах() | |
| pagecount | Количество страниц парсинга() | |
| parsecodes | Значение кодов ответов для запросов которые будут считаться успешными() | |
| queryformat | Формат запроса() |
Что такое парсер аудиторий?
Если вручную искать всех людей из целевой аудитории с копированием их контактов в специальные таблицы, то это займёт слишком много времени. Часто такие списки состоят из десятков тысяч людей, численность в 2000-3000 человек для многих сегментов является минимальной. Чтобы автоматизировать парсинг, создаются специальные программы – парсеры.
Парсер аудиторий находит пользователей, собирает информацию о них, анализирует, а если человек подходит по указанным заранее параметрам, то его контакты и другие данные записываются в таблицы или списки. Готовый результат парсинга можно скачать в файле.
Кроме того, парсеры могут находить не конкретных людей целевой аудитории, а группы и сообщества в инстаграм, instagram, facebook, где общаются потенциальные клиенты.
Критериями для выбора группы являются:
- ключевые слова в сообщениях пользователей;
- географическое положение аудитории;
- присутствие различных меток;
- интересы аудитории.
Для поиска отдельных клиентов можно анализировать гораздо больший спектр информации:
- имена, фамилии;
- пол, возраст;
- родственные связи, наличие престарелых родителей, а также количество детей (их пол);
- место жительства, место работы;
- должность, профессия, образование;
- подписки на различные группы;
- любимые книги, музыка, фильмы, другие увлечения;
- статус (в браке, в поиске, учёба, карьера и прочее);
- некоторые парсеры могут анализировать фотографии, аудио, видео.
await this.parser.request(parser, preset, overrideParams, query)#
awaitthis.parser.request(parser, preset, overrideParams, query)
Скопировать
Получение результатов от другого парсера (встроенного или еще другого JS парсера), в качестве аргументов указывается
- — имя парсера (SE::Google, JS::Custom::Example)
- — пресет настроек вызываемого парсера
- — хэш с переопределениями настроек вызываемого парсера
- — запрос
В overrideParams, кроме параметров вызываемого парсера, дополнительно можно передать флаг — он позволяет возвращать массив объектов в результатах вместо стандартного массива значений
Пример:
import{BaseParser}from’a-parser-types’;
classJS_DocExampleextendsBaseParser{
static defaultConftypeofBaseParser.defaultConf={
results_format»$links.format(‘$link\n’)»,
results{
flat
‘title’,’Title’,
,
arrays{
links’Links’,
‘link’,’link’,
,
}
}
}
asyncparse(set, results){
let response =awaitthis.parser.request(‘SE::Google’,’default’,{
resultArraysWithObjects1,
proxyretries100,
pagecount1
},set.query)
if(response.success){
response.serp.forEach(element =>{
results.links.push(element.link);
});
}
results.success=1;
return results;
}
}
Скопировать
Пример результата:
Работа с cookies для текущего запроса
Получение массива cookies
awaitthis.cookies.getAll();
Скопировать
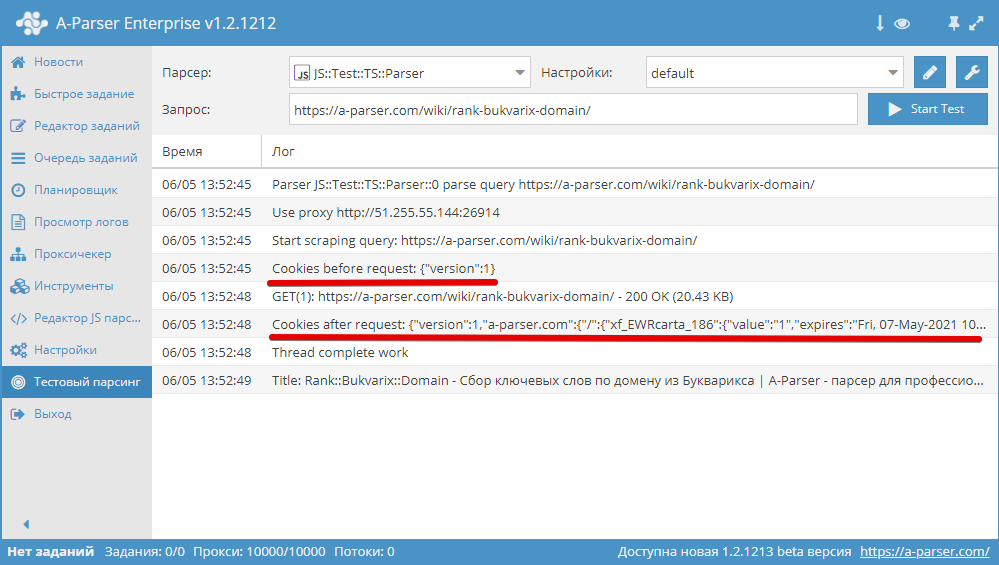
Установка cookies, в качестве аргумента должен быть передан массив с cookies
asyncparse(set, results){
this.logger.put(«Start scraping query: «+set.query);
awaitthis.cookies.setAll(‘test_1=1′,’test_2=2’);
let cookies =awaitthis.cookies.getAll();
this.logger.put(«Cookies: «+JSON.stringify(cookies));
results.SKIP=1;
return results;
}
Скопировать

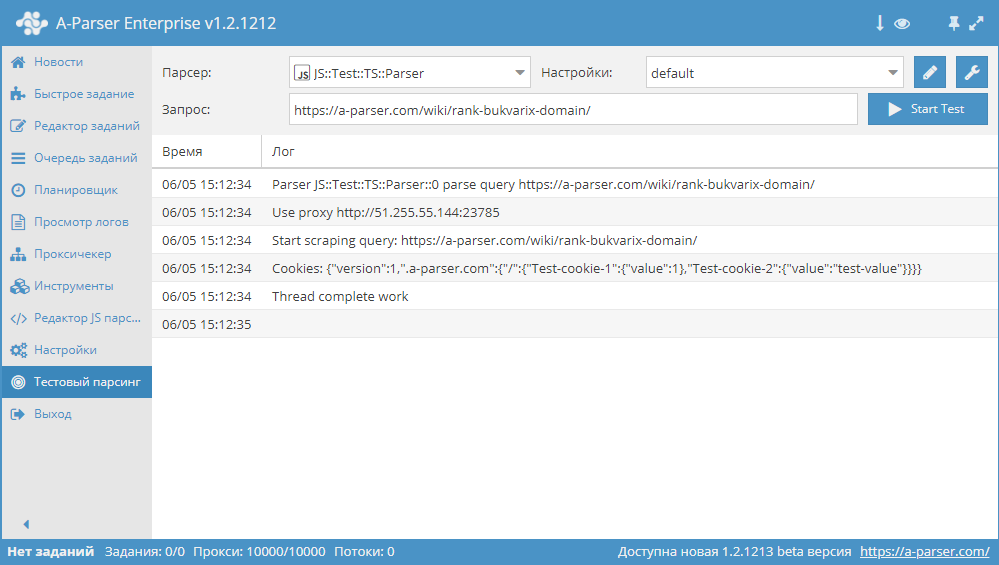
— установка одиночного cookie
asyncparse(set, results){
this.logger.put(«Start scraping query: «+set.query);
awaitthis.cookies.set(‘.a-parser.com’,’/’,’Test-cookie-1′,1);
awaitthis.cookies.set(‘.a-parser.com’,’/’,’Test-cookie-2′,’test-value’);
let cookies =awaitthis.cookies.getAll();
this.logger.put(«Cookies: «+JSON.stringify(cookies));
results.SKIP=1;
return results;
}
Скопировать
Zeus
Только Инстаграм (1 соцсеть). Имеется несколько сервисов, в том числе и Инстаграм парсер.
Чтобы использовать парсер в правом углу переключитесь на “Инстаграм парсер” и нажмите “добавить задачу”, а далее выберите нужную функцию.
Основной функционал парсера:
- Сбор: аудитории по хештегу, фолловеров аккаунта, подписок аккаунта, аудитории по файлу, по комментариям поста, лайкнувших пост, с геолокации
- Способ фильтрации информации: базовая фильтрация или данные из Вк
- Способ обработки данных: перевод id-username; username-id
- Выгрузка данных: txt файл, excel файл, включая информацию о номерах телефонов
Зачем парсить группы в Фейсбуке крупнейшая социальная сеть в мире и одноимённая компания (Facebook Inc.), владеющая ею. Была основана 4 февраля 2004 года Марком Цукербергом и его соседями по комнате во время обучения в
Таргетированная реклама работает и без парсинга, но при тех же вложениях конверсия будет ниже. Это происходит из-за того, что параметры настройки рекламного кабинета могут предусмотреть многое, но не всё. Ни один таргет не гарантирует на 100%, что профили, подходящие под кампанию по критериям — потенциальные клиенты Клиент (от лат. cliens, множ. clientes) — в Древнем Риме свободный гражданин, отдавшийся под покровительство патрона и находящийся от него в зависимости.
Потому, основная цель парсинга в Facebook — обеспечить безошибочное попадание в целевую аудиторию.
Смысл в следующем. Допустим, вы издали кулинарную книгу и ищете целевую аудиторию для рекламы. Настраиваете таргет на замужних женщин от 25 до 36 лет. Уверены ли вы, что все такие женщины интересуются кулинарией? Большая часть, но не все, конечно же. А почему бы не запустить показ и на мужчин, ведь среди них тоже есть любители готовить? Будет не эффективно, так как в этом сегменте кулинария — довольно редкое увлечение.
Зато вы находите группу в Facebook, которая называется «Кулинарные рецепты на все случаи жизни» и в ней состоит 150 тыс. подписчиков. Эти люди уже заявили, что интересуются темой. Как вы думаете, было бы эффективно показать рекламное объявление кулинарной книги именно им?
Парсинг анализ (или разбор, жарг позволит вам выгрузить список пользователей Facebook, подписанных на группу в рекламный кабинет рабочая комната, предназначенная для письменных занятий, интеллектуальной работы и другого социальной сети, чтобы запустить кампанию с ретаргетингом по этой аудитории.
Помимо этого, у парсеров, могут быть и другие функции отношение между элементами, при котором изменение в одном элементе влечёт изменение в другом: Функция (философия) — обязанность, круг деятельности:
- Поиск сообществ конкурентов, для парсинга потенциальных клиентов (по ключевым словам, количеству подписчиков, интересам, вероисповеданию, количеству контента).
- Парсер поможет выгрузить пользователей по параметрам, которых нет в рекламном кабинете: родителей по возрасту детей; жён, чьи мужья празднуют день рождения основное понятие биологии — активная форма существования материи, в некотором смысле высшая по сравнению с её физической и химической формами существования; совокупность физических и химических через неделю; людей, поставивших лайк/сделавших репост на контент, аналогичный вашему.
- Сбор многозначное слово базы База — место временного хранения товаров, например: «овощная база» телефонов/почт/аккаунтов в соцсетях потенциальных клиентов для загрузки в рекламный кабинет и создания look a like аудитории.
- Мониторинг сообществ конкурентов: можно настроить показ рекламы направление в маркетинговых коммуникациях, в рамках которого производится распространение информации для привлечения внимания к объекту рекламирования с целью формирования или поддержания интереса новым подписчикам той или иной группы или, наоборот, людям, покинувшим её.
static parserOptions#
является альтернативным вариантом задания настроек, список опций отображается как дополнительные пункты в контекстном меню парсера
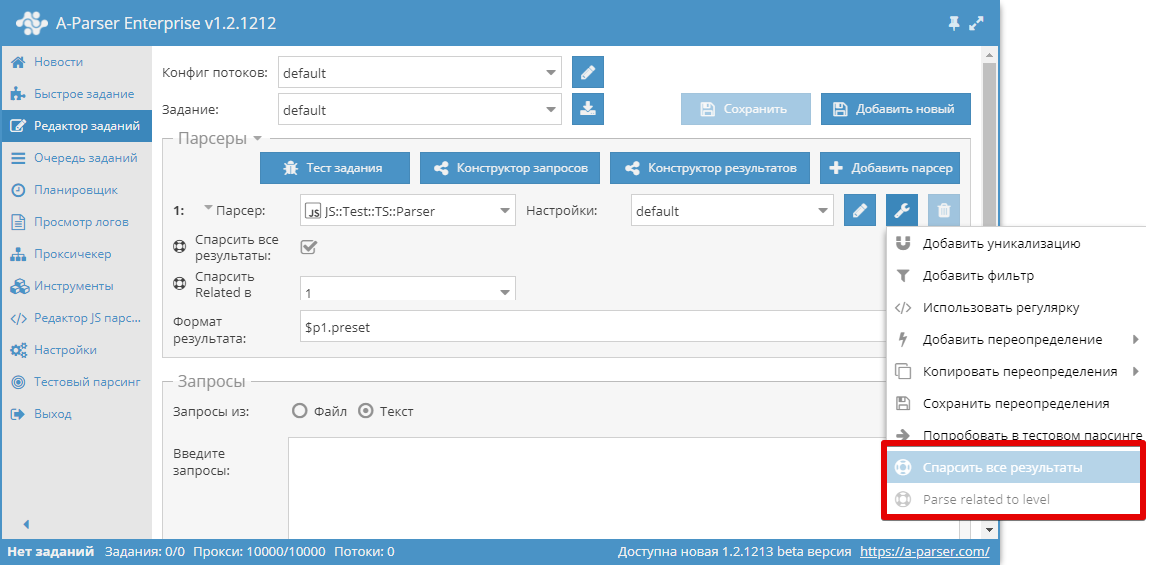
Декларирование опций работает аналогично :
static parserOptions
fieldNamestring,
menuTitlestring,
fieldConfig
fieldType’textfield’|’combobox’|’checkbox’,
fieldLabelstring,
fieldOptions?{},
…fieldValuesfieldValueany, valueTitlestring
;
Скопировать
Пример:
static parserOptionstypeofBaseParser.parserOptions=
‘parseAll’,’Parse all results’,
‘checkbox’,’Parse all results’
,
‘parseLevel’,’Parse related to level’,
‘combobox’,’Parse Related to level’,1,1,2,2,3,3
,
;
Скопировать
Виды парсеров по технологии
Браузерные расширения
Для парсинга данных есть много браузерных расширений, которые собирают нужные данные из исходного кода страниц и позволяют сохранять в удобном формате (например, в XML или XLSX).
Парсеры-расширения — хороший вариант, если вам нужно собирать небольшие объемы данных (с одной или парочки страниц). Вот популярные парсеры для Google Chrome:
- Parsers;
- Scraper;
- Data Scraper;
- Kimono.
Надстройки для Excel
Программное обеспечение в виде надстройки для Microsoft Excel. Например, ParserOK. В подобных парсерах используются макросы — результаты парсинга сразу выгружаются в XLS или CSV.
Google Таблицы
С помощью двух несложных формул и Google Таблицы можно собирать любые данные с сайтов бесплатно.
Эти формулы: IMPORTXML и IMPORTHTML.
IMPORTXML
Функция использует язык запросов XPath и позволяет парсить данные с XML-фидов, HTML-страниц и других источников.
Вот так выглядит функция:
Функция принимает два значения:
- ссылку на страницу или фид, из которого нужно получить данные;
- второе значение — XPath-запрос (специальный запрос, который указывает, какой именно элемент с данными нужно спарсить).
Хорошая новость в том, что вам не обязательно изучать синтаксис XPath-запросов. Чтобы получить XPath-запрос для элемента с данными, нужно открыть инструменты разработчика в браузере, кликнуть правой кнопкой мыши по нужному элементу и выбрать: Копировать → Копировать XPath.

С помощью IMPORTXML можно собирать практически любые данные с html-страниц: заголовки, описания, мета-теги, цены и т.д.
IMPORTHTML
У этой функции меньше возможностей — с ее помощью можно собрать данные из таблиц или списков на странице. Вот пример функции IMPORTHTML:
Она принимает три значения:
- Ссылку на страницу, с которой необходимо собрать данные.
- Параметр элемента, который содержит нужные данные. Если хотите собрать информацию из таблицы, укажите «table». Для парсинга списков — параметр «list».
- Число — порядковый номер элемента в коде страницы.
CleverTarget
Для какой соцсети: ВКонтакте
Какие возможности предоставляет CleverTarget:
- Поиск аудитории: пожалуй, самая ожидаемая функция парсера. Поиск осуществляется по различным критериям.
- Управление: благодаря этому функционалу вы можете отслеживать новые комментарии и сообщения в группах ВКонтакте, не заходя в социальную сеть.
- Облачное решение: чтобы собирать аудиторию, необязательно быть онлайн, вы можете делать это в автономном режиме. Кроме того, все данные и отчёты хранятся в облаке, что позволяет возвращаться к ним в любое удобное время.
- Создание объявлений: если парсеры, которые были описаны выше, могли только находить аудиторию, то этот сервис позволяет в том числе создавать объявления.
Отдельная опция — прогнозирование ставок для размещения объявления с помощью искусственного интеллекта. Также парсер представляет инструмент для анализа конкурентов: оценивает активность в их сообществах, качество аудитории и т.д.
Стоимость: оплата посекундная — вы платите только за время работы в сервисе. Есть пробный период.
Оксана Михалко, руководитель группы digital-стратегов Ingate
Прежде чем приступать к парсингу пользователей, вы должны чётко определить, кто ваша целевая аудитория. Это существенно упростит работу, так как для каждого типа потенциального клиента вы сможете задать свои настройки таргетинга. В результате вероятность того, что реклама покажется тем пользователям, которые в ней действительно заинтересованы, повышается в разы. Как следствие, конверсия тоже будет выше. Собранную базу пользователей также можно использовать для настройки ретаргетинга в соцсетях.
await this.sessionManager.*#
Для использования сессий в JS парсере сначала нужно инициализировать Менеджер сессий. Делается это с помощью функции
asyncinit(){
awaitthis.sessionManager.init({
});
}
Скопировать
В можно использовать следующие параметры:
- — необязательный параметр, позволяет переопределить имя парсера, которому принадлежат сессии, по-умолчанию равно имени парсера, в котором происходит инициализация
- — необязательный параметр, возможность менять прокси, по-умолчанию равно 1
- — необязательный параметр, указывает искать сессии среди всех сохраненных для этого парсера (если значение не задано), или же только для конкретного домена (необходимо указывать домен с точкой спереди, например )
Для работы с сессиями существует несколько функций:
— получает новую сессию, необходимо вызывать перед осуществлением запроса
— очистка куков и получение новой сессии. Необходимо вызывать, если с текущей сессией запрос не был удачным.
— сохранение удачной сессии либо сохранение произвольных данных в сессии
Пример сохранения произвольных данных и дальнейшего их получения:
asyncinit(){
awaitthis.sessionManager.init({
});
}
asyncparse(set, results){
this.logger.put(«Start scraping query: «+set.query);
let ua =’Mozilla/5.0 (Windows NT 10.0; Win64; x64)’;
let referer =set.query;
let data =’Some data’;
awaitthis.sessionManager.save({ua, referer, data});
let session =awaitthis.sessionManager.get();
this.logger.put(«Session: «+JSON.stringify(session));
results.SKIP=1;
return results;
}
Скопировать

Для групп + сбора email … и прочего

Поговорим о лучших сервисах: парсеры для получения данных из фейсбук в 2020 году.
—FBSender
Удобный парсер аудитории в facebook, предоставляет полезные инструменты:
- список подписчиков групп или страниц конкурентов;
- поиск людей с определенными характеристиками;
- выборка пользователей, поставивших лайк/написавших комментарий;
- посты по ключевым словам или по комментариям;
- список групп по названию/теме/количеству подписчиков.

Плюсы: Хороший парсер для фейсбука, работает бесплатно, понятный интерфейс, полностью на русском языке. Позволяет устанавливать задержку действий, для обхода алгоритмов фейсбука.
Минусы: Для работы через эту программу рекомендуется использовать прокси или VPN, а также платные сервисы анти-капча.
—PepperNinja
Пожалуй, лучший из онлайн-сервисов для сбора данных. Специализируется в первую очередь на Вконтакте, но эффективен и как парсер фб, инста и ОК. Работает в этой области достаточно давно, постоянно развивается и заслуживает доверия.
Набор функций:
- можно отобрать друзей конкретного человека, подписчиков страницы или участников группы;
- находит ID профилей в фейсбуке по ссылкам на аккаунты Инстаграма;
- фильтрует готовую выборку от ботов и заброшенных аккаунтов;
- позволяет составить аудиторию по детальным характеристикам.

Сервис платный, для ВК есть пробный период, но с фейсбуком работа намного сложнее, поэтому опции для этой соцсети приобретаются отдельно. Минимальный пакет на один месяц стоит 490 р., а профессиональный на год – почти 15 000. А для того чтобы понять, нужен ли вам вообще парсер для фейсбука, вы можете купить начальный пакет на два дня всего за 190 р.
Плюсы: большая надежность и профессиональный подход.
Минусы: Высокая цена, поиск аудитории только в России и СНГ.
—FB TARGET


—Netpeak Checker
Большой мульти-инструмент для анализа и сравнения поисковых систем, сайтов и социальных сетей. В том числе, его можно использовать и как facebook parser: так как сканер позволяет узнать количество уникальных ссылок на заданной странице, он способен собрать ID подписчиков. Доступ платный, от $19 в месяц.
Плюсы: используя этот сервис, вы избежите бана от ФБ (он позволяет обходить ограничения).
Минусы: аккаунты нельзя отфильтровать от ботов, для парсинга только одна полезная функция.
—FB Group Parse Pro
Удобный макрос для браузера Firefox. Он предназначен для составления списка групп по количеству участников. Как это работает:
- Необходимо задать поиск групп на сайте фейсбук по ключевому слову.
- Запустить макрос, задав критерий для отбора – количество пользователей.
- По итогам формируется документ .xls с необходимым списком.
Cтоимость составляет $6.99
Плюсы: простой и быстрый, не фиксируется системой контроля ФБ.
Минусы: работает только с одним браузером.
Мощный парсер номеров работает с поисковиками и почтовыми ящиками, а также идеально подходит для фейсбук. Лицензия на ПО стоит $49 для персонального использования на одном ПК. Но после покупки далее все функции станут полностью доступны:
- номера;
- адреса электронной почты;
- аккаунты в других соц.сетях;
- отбор по интересам, профессии, стране и городу, языку;
- отбор по лайкам и комментам;
- поиск данных пользователей на основном сайте страницы или группы;
- проверка ID пользователя в поисковиках с целью поиска контактов.
Плюсы: в отличие от онлайн-сервисов, не имеет ограничений по количеству запросов и результатов.
Минусы: не сканирует страницы крупных компаний, иногда не может обойти ограничения facebook, не фильтрует контакты от одноразовых и неактивных.
Подведем итоги:
Как видно из описания самых популярных программ, каждая из них направлен на решение своих конкретных задач. Опытные арбитражники сочетают работу разных сервисов, чтобы получить максимальный результат.
Несмотря на стоимость большинства программ, такие затраты оправданы существенной экономией на рекламе. Чем больше попаданий в цель будет у вашего объявления, чем больше взаимодействий оно вызовет – тем меньше денег будет потрачено на рекламную кампанию.
С чего начать работу в Фейсбуке
Если вы хотите вести бизнес или найти работу, то с самого начала проработайте концепцию своей личной страницы. По ней другим должно было понятно, чем вы занимаетесь и какие услуги предлагаете.
После регистрации я пару лет просто делала репосты постов из блога в ЖЖ на личную страницу. Это было абсолютно бесполезное занятие, потому что по внешним ссылкам/репостам в Фейсбуке перейдут лишь если вы:
а) сопроводили их интересной подводкой;
б) разместили что-то архиполезное;
в) проверенный человек, которому доверяют.
Вскоре один знакомый порекомендовал мне оживить страницу с помощью массфрендинга. «Добавляй всех. Тебе нужно просто набрать критическую массу», – сказал он. Я засела со смартфоном и стала добавлять всех его друзей. Несколько человек спросило знакомы ли мы и чего я хочу. Внятно ответить мне было сложно, потому что я даже не смотрела профили перед добавлением.
Многие новички начинают именно с этого способа. Я его не рекомендую – вы рискуете подписаться на людей, которые никогда не станут вашей целевой аудиторией. В моем случае это были украинцы с пустыми страницами, которых потом пришлось долго и нудно вычищать из друзей. А еще такие «друзья» начинают спамить и добавлять вас в странные группы.
Кроме того, в Фейсбуке существует ограничение на 5000 друзей. Поэтому для роста популярности гораздо лучше добавлять заинтересованных пользователей из вашей ниши, которые связаны с вами общими занятиями.
Итак, чтобы начать эффективную работу по продвижению в Фейсбуке, нужно:
- Внятно написать о себе на своей странице. Кто вы и что предлагаете.
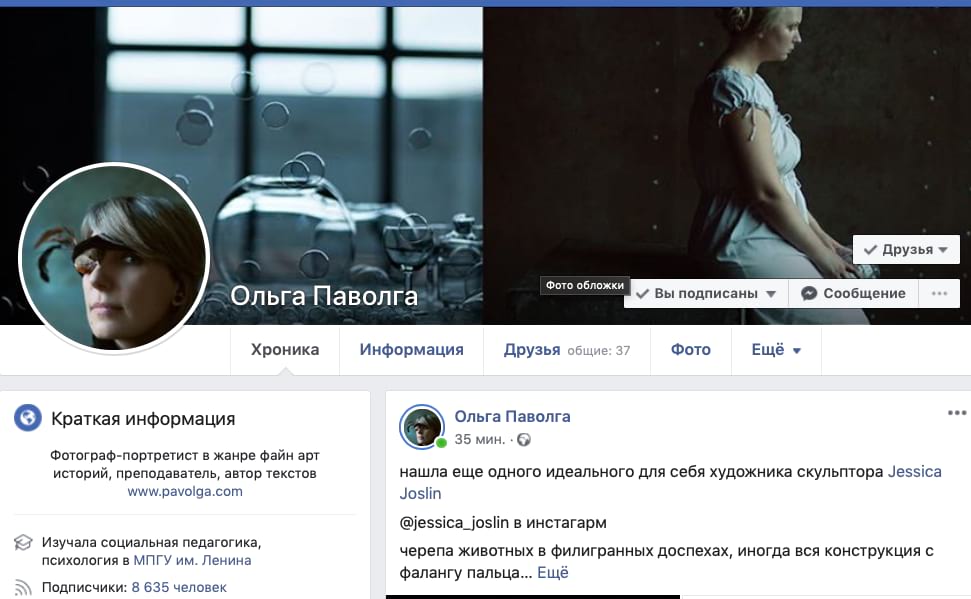 Хороший пример адекватного оформления личной страницы в Фейсбуке. Сразу понятно, что Ольга фотограф
Хороший пример адекватного оформления личной страницы в Фейсбуке. Сразу понятно, что Ольга фотограф
Смело добавлять в друзья незнакомых людей, но перед этим оценивая их профили
Важно! Когда вы добавляете кого-то, то автоматически оформляете подписку. Чтобы избежать мусора в ленте, можете отписаться от его обновлений без удаления из друзей:
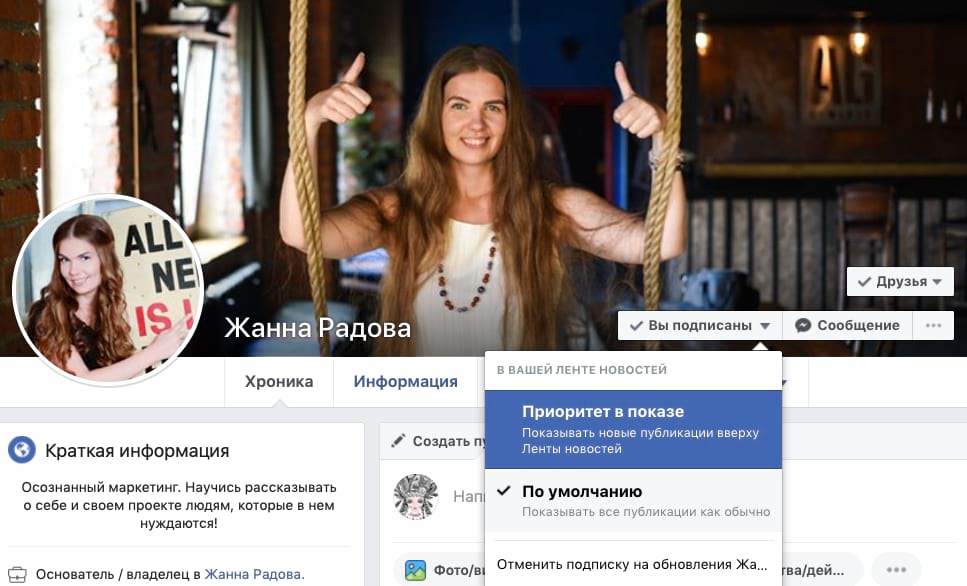 А для интересных пользователей вы можете выбрать параметр – «Приоритет в показе»
А для интересных пользователей вы можете выбрать параметр – «Приоритет в показе»
-
Вступать в тематические группы, в которых можно найти единомышленников и потенциальных клиентов. Для этого воспользуйтесь поиском по группам и страницам (в Фейсбуке есть возможность отфильтровать по городу):
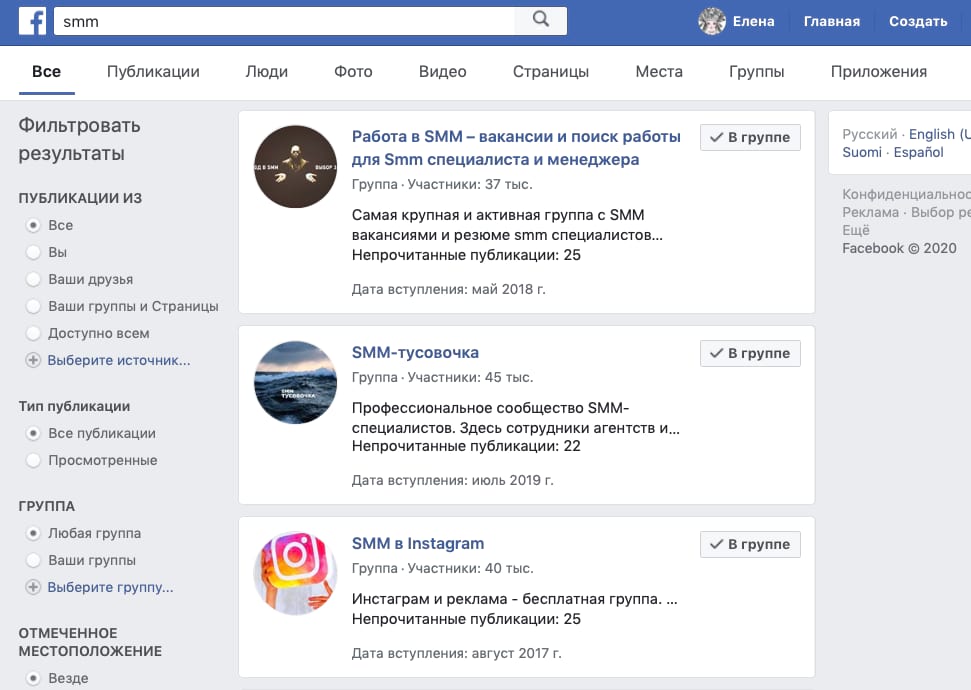 Вбейте в поиске название вашей ниши, чтобы найти группы и страницы по теме
Вбейте в поиске название вашей ниши, чтобы найти группы и страницы по теме
-
Попросить друзей порекомендовать вам полезные группы.
-
Сделать свою страницу местом общения с единомышленниками.
Например, художница Мирта Гроффман много лет продает картины, даже не имея сайта. Ей удалось создать собственное уютное комьюнити. На личной странице она откровенно рассказывает о приемном родительстве, воспитании десяти детей, творчестве и отношениях. Цены на картины высокие, но они все равно разлетаются как горячие пирожки.
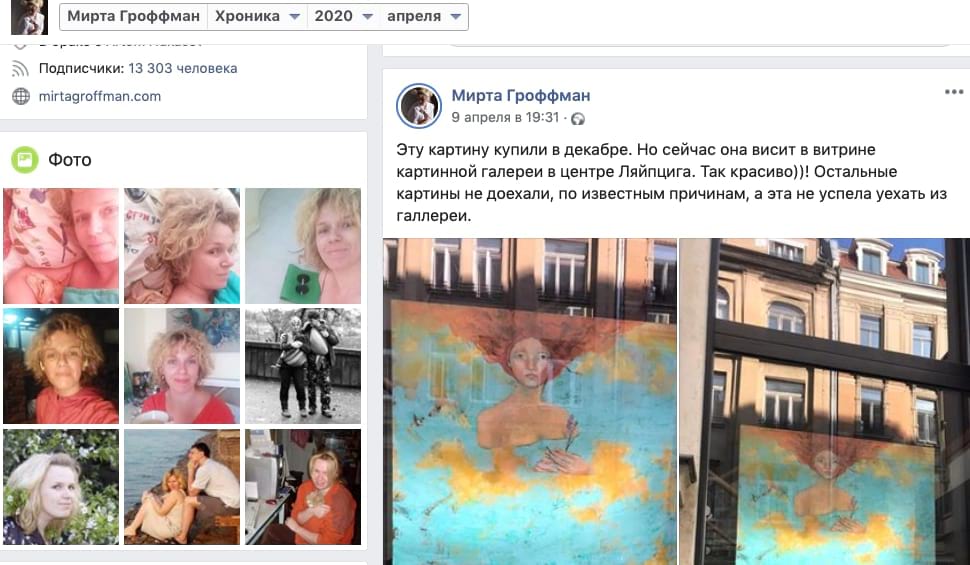 Людей подкупает искренность и харизма, которая стоит за работами Мирты
Людей подкупает искренность и харизма, которая стоит за работами Мирты
Воспринимайте Фейсбук как живое сообщество профессионалов, клиентов, заказчиков и работодателей. Здесь люди среднего возраста делятся своей частной жизнью и рабочими моментами, но при этом ищут работу или предлагают ее, а также готовы покупать что-то интересное и аутентичное.
Как осуществляется парсинг?
Если приложение является десктопным, то перед использованием его нужно скачать и установить на компьютере. Если программа работает в инстаграм онлайн на удалённых серверах, то нужна авторизация на сайте компании, которая предоставляет парсер аудитории. Обычно при первом запуске приложения появляется окно, где можно почитать, как пользоваться программой. Не игнорируйте эту возможность, лучше сразу ознакомьтесь с нюансами работы.
Для запуска парсера аудитории нужно настроить параметры поиска. Здесь всё индивидуально, возможности по настройке критериев у каждого приложения свои. Обычно сразу же предлагается выбрать, что нужно сделать с результатом парсинга: сохранить в БД или сразу же экспортировать в файл и сохранить на компьютер (для онлайн приложения – передать по почте).
После запуска программы парсер начнёт работу самостоятельно, не требуя вмешательства. Собирать информацию в инстаграм он может долго, в зависимости от количества людей, групп и числа социальных сетей время может колебаться от нескольких часов до суток. Результат парсинга будет доступен через базу данных, также его можно экспортировать в файл в удобном формате (рекомендуется excel).
Какие существуют парсеры?
Существует множество систем классификации парсеров аудитории. Необходимо рассмотреть каждый способ, чтобы выбрать наиболее подходящее приложение для инстаграм:
Преимущества онлайн парсеров аудитории:
- они могут использовать большие мощности;
- в случае ЧП неполадки устраняются быстрее (в теории), так как за работой программы наблюдают специалисты;
- они всегда онлайн и работают 24 часа, 7 дней в неделю;
- при работе не нагружают компьютер, не нужно ждать, когда программа завершит работу.
Недостатки онлайн парсеров аудитории:
- приложение находится в руках другого человека, который может менять программу, её дизайн, функции, не посоветовавшись с вами;
- если с фирмой, которая поддерживает приложение, что-то случится, то парсер прекратит свою работу.
Преимущества десктопных парсеров аудитории:
- он находится на вашем компьютере, полностью принадлежит вам, никакие изменения в нём не будут происходить без вашего согласия;
- вы платите один раз, в дальнейшем никаких изменений ежемесячной платы не будет.
Недостатки десктопных парсеров аудитории:
- приложение ограничено мощностями компьютера, если ПК старый, то будут проблемы;
- в случае ЧП придётся обращаться к разработчику, не факт, что удастся быстро связаться;
- для нормальной работы парсеру нужно, чтобы компьютер работал 24 часа в сутки и имел постоянный доступ к интернету.
Разумеется, главное требование к парсеру – чтобы он покрывал всю целевую аудиторию.
static editableConf#
Данная настройка задает список полей конфигурации, которые могут быть отредактированы через интерфейс. Сущесвтуют следующие типы полей в интерфейсе:
- — поле для произвольного ввода числовых и строковых значений
- — флаг с состояниями включен/выключен
- — дропдаун с выбором одного или нескольких значений
- выбор нескольких значений задается через опцию
представляет из собой массив, каждый элемент которого описывает соответсвующее поле конфигурации:
static editableConf
fieldNamestring,
fieldConfig
fieldType’textfield’|’combobox’|’checkbox’,
fieldLabelstring,
fieldOptions?{},
…fieldValuesfieldValueany, valueTitlestring
;
Скопировать
Пример объявления редактируемых полей:
staticgeteditableConf(){
let editableConftypeofBaseParser.editableConf=
‘device’,
‘combobox’,’Device’,
‘desktop’,’Modern desktop computer (Windows 10, Chrome 84)’,
‘mobile’,’Mobile device (iPhone X, iOS 11)’
,
‘pagecount’,’combobox’,’Pages count’,
‘linksperpage’,
‘combobox’,’Links per page’,
10,’10’,
20,’20’,
30,’30’,
50,’50’
,
;
for(let page =1; page <=25; page++)
editableConf11.push(page, page);
return editableConf;
}
Скопировать
note
Обратите внимание, в данном примере использован метод-геттер для editableConf, что позволяет производить дополнительную обработку, например генерацию списка страниц. Для более простых случаев вы можете задавать статичное свойства класса, аналогично как и для defaultConf
Segmento Target
Работает с 3-мя соцсетями: Парсер Вконтакте, Инстаграм и Одноклассники.

Основной функционал парсера:
- Поиск (групп/контакты, контакты сообществ, поиск пользователей, участников сообществ и встреч, посты в новостях, группы где есть ЦА, друзей и подписчиков, лидеров мнений и пр.)
- Активная аудитория (сообществ/пользователей/обсуждений/постов/фотоальбомов/тоа активных/виджетов на сайтах и пр.)
- Сбор (промопостов, постов юзеров, опросов, номеров телефонов, скайпов, инстаграмов и пр.).
- Некоторые возможно парсера разнятся/имеют более расширенный функционал, в зависимости от соцсети
Из интересных особенностей – есть база тизеров по каждой соцсети, а также видео-уроки по популярным фунциям и кейсы (своя база знаний). Также есть: очистка от ботов, аналитика и фильтрация аудитории, гео-таргетинг в Инстаграм, поиск аккаунтов/ID Инстаграм из базы пользователей ВКонтакте, управление объявлениями Вк.
Сервис предлагает бесплатный доступ, без ограничений по срокам. Бесплатный доступ позволяет изучить парсер, его возможности и функционал. Скачать результат можно после оплаты.
При новой регистрации сервис дарит + 25% дней, при оплате любого тарифа!
ссылка на сервис Segmento Target
Церебро Таргет
Поиск аудитории для таргетинга Вк (1 соцсеть).

Основной функционал парсера:
- Поиск аудитории (группы, где есть ЦА, популярные люди, анализ пользователей)
- Аудитория сообществ (участники/активности/контакты сообществ, топ читателей и комментаторов, друзья аудитории, фотоальбомы и пр.)
- Сообщества (поиск и фильтр, поиск постов), парсинг по профилю пользователей (репосты со стены, друзья и подписчики, активности, Инстаграм и пр.)
- Фильтр баз (пересечение и аналитика аудиторий, поиск по базе, пересечение сегментов)
А также: сбор голосовавших в опросах/комментариев с сайта (оставленных через виджет Вк), поиск по новостям (по списку групп и фраз), удобный просмотр людей из собранных баз.
Из интересного: есть ЦереброТаргет – Flash-версия (более 55 модулей для работы прямо в Вк), кейсы от читателей сообщества, а также закрытая обучающая группа с мощной базой.
Вообще у сервиса нет бесплатного тестового периода. Но пока еще идет временная акция: если подписаться на их обучающий интенсив () – в ответ придет сообщение с уникальной ссылкой, по которой можно получить доступ к Церебро по тарифу Premium на 5 дней (когда будете заходить на сайте – нажимаете “войти” и в выпадающем меню выбрать “Церебро PRO”).
Ссылка на Церебро Таргет
async parse(set, results)#
Метод реализует основную логику обработки запроса и получения результата парсинга, в качестве аргументов передаются:
-
— объект с информацией о запросе:
- — текстовая строка запроса
- — уровень запроса, по умолчанию
-
— объект с результатами, которые необходимо заполнить и вернуть из метода parse()
- парсер должен проверять наличие каждого ключа в объекте results и заполнять его только при наличии, таким образом оптимизируется скорость и парсятся только те данные, которые используются в формировании результата
- содержит ключи необходимых flat переменных со значением , по умолчанию это означает что результат не получен, а также ключи переменных-массивов(arrays) со значением в виде пустого массива, готового для заполнения
- должен устанавливаться в значение при успешной обработке запроса, по умолчанию значение , означающее что запрос обработан с ошибкой
Разберем на примере:
classJS_HTML_TagsextendsBaseParser{
static defaultConf ={
results{
flat
‘title’,’Title’,
,
arrays{
h2’H2 Headers List’,
‘header’,’Header’,
,
}
},
…
};
asyncparse(set, results){
const{success, data, headers}=awaitthis.request(‘GET’,set.query);
if(success &&typeof data ==’string’){
let matches;
if(results.title&& matches = data.match(<title*>(.*?)<\/title>))
results.title= matches1;
if(results.h2){
let count =;
const re =<h2*>(.*?)<\/h2>g;
while(matches = re.exec(data)){
results.h2.push(matches1);
}
}
results.success=1;
}
return results;
}
};
Скопировать
Обратите внимание что вы можете создавать собственные функции и методы для лучшей организации кода:
functionAnswer(){
return42;
}
classJS_HTML_TagsextendsBaseParser{
…
asyncparse(set, results){
results =awaitthis.doWork(set, results);
return results;
}
asyncdoWork(set, results){
results.answer=Answer();
return results;
}
};
Скопировать