Аналитика для telegram-ботов, написанных на python
Содержание:
- Краткое введение в NLKT
- pyTelegramBotApi
- Шаг 8: реализация обработчика кнопки обновления
- Недостатки с нашим ботом
- Как скачать и отправить стикер пользователю из Telegram бота
- Взаимодействуя с нашим ботом через ваш веб-браузер
- Готовим программу и отправляем её на сервер
- Создаём проект
- Где взять данные для обучения
- Как работает чат-бот?
- Telebot и сила python
- Как работают Instagram боты
- Подключаем библиотеку и получаем сообщения
- Соединение
- Заключение
Краткое введение в NLKT
NLTK (Natural Language Toolkit) — платформа для создания программ на Python для работы с естественной речью. NLKT предоставляет простые в использовании интерфейсы для более чем 50 корпораций и лингвистических ресурсов, таких как WordNet, а также набор библиотек для обработки текста в целях классификации, токенизации, генерации, тегирования, синтаксического анализа и понимания семантики, создания оболочки библиотек NLP для коммерческого применения.
Книга Natural Language Processing with Python — практическое введение в программирование для обработки языка. Рекомендуем ее прочитать, если вы владеете английским языком.
Загрузка и установка NLTK
- Установите NLTK: запустите pip install nltk.
- Тестовая установка: запустите python, затем введите import nltk.
Инструкции для конкретных платформ смотрите здесь.
Установка пакетов NLTK
Импортируйте NLTK и запустите nltk.download(). Это откроет загрузчик NLTK, где вы сможете выбрать версию кода и модели для загрузки. Вы также можете загрузить все пакеты сразу.
Предварительная обработка текста с помощью NLTK
Основная проблема с данными заключается в том, что они представлены в текстовом формате. Для решения задач алгоритмами машинного обучения требуется некий вектор свойств. Поэтому прежде чем начать создавать проект по NLP, нужно предварительно обработать его. Предварительная обработка текста включает в себя:
- Преобразование букв в заглавные или строчные, чтобы алгоритм не обрабатывал одни и те же слова повторно.
- Токенизация. Токенизация — термин, используемый для описания процесса преобразования обычных текстовых строк в список токенов, то есть слов. Токенизатор предложений используется для составления списка предложений. Токенизатор слов составляет список слов.
Пакет NLTK включает в себя предварительно обученный токенизатор Punkt для английского языка.
- Удаление шума, то есть всего, что не является цифрой или буквой;
- Удаление стоп-слов. Иногда из словаря полностью исключаются некоторые крайне распространенные слова, которые, как считается, не имеют большого значения для формирования ответа на вопрос пользователя. Эти слова называются стоп-словами (междометия, артикли, некоторые вводные слова);
- Cтемминг: приведение слова к коренному значению. Например, если нам нужно провести стемминг слов «стемы», «стемминг», «стемированный» и «стемизация», результатом будет одно слово — «стем».
- Лемматизация. Лемматизация — немного отличающийся от стемминга метод. Основное различие между ними заключается в том, что стемминг часто создает несуществующие слова, тогда как лемма — это реально существующее слово. Таким образом, ваш исходный стем, то есть слово, которое получается после стемминга, не всегда можно найти в словаре, а лемму — можно. Пример лемматизации: «run» — основа для слов «running» или «ran», а «better» и «good» находятся в одной и той же лемме и потому считаются одинаковыми.
pyTelegramBotApi
Ссылки на документации всех библиотек будут в конце.
Создадим простого бота, отвечающего на команду , с помощью этой библиотеки:
pyTelegramBotApi является просто обёрткой для всего Telegram Bot API, но здесь разберутся только основные составляющие.Взаимодействие с ботом происходит через переменную bot (токен надо вставить свой). Декоратор @message_handler реагирует на входящие сообщение.Message – это объект из Bot API, содержащий в себе информацию о сообщении. Полезные поля: message.chat.id – идентификатор чатаmessage.from.id – идентификатор пользователяmessage.text – текст сообщенияФункция send_message принимает идентификатор чата (берем его из сообщения) и текст для отправки.
Замена клавиатуры
У ботов есть функция замены стандартной клавиатуры на кнопочную. Для этого у всех функций есть опциональный аргумент reply_markup:
ReplyKeyboardMarkup – и есть та самая клавиатура. Метод row() создает ряд (максимум 12) из кнопок, передаваемых в качестве аргумента.Также есть особенная клавиатура types.ReplyMarkupRemove(), которая меняет клавиатуру на стандартную.
Клавиатура для сообщений
Можно создавать клавиатуру для отдельного сообщения. Передавать его нужно так же в аргумент reply_markup:
У кнопок есть несколько режимов, в зависимости от второго аргумента. Подробнее можно прочитать в официальной документации, но я остановлюсь только на callback_data.При нажатии на такую кнопку боту придет отдельный CallbackQuery, который нужно обрабатывать подобно сообщению:
Для обработки обязательно указать аргумент func для «отсеивания» Callback запросов.После обработки каждого запроса нужно выполнить команду answer_callback_query, чтобы Telegram понял, что запрос обработан. В поле callback.data хранится информация из callback_data нажатой кнопки.
Изменение сообщений
У ботов есть функция изменения своих сообщений (можно использовать, чтобы сделать перелистывание страниц, например). Для этого нужно воспользоваться методом edit_message_text (edit_message_caption для картинок):
Смысл аргументов понятен из их названия.
Шаг 8: реализация обработчика кнопки обновления
Напишем код для обработки действий с кнопкой Update и дополним его часть iq_callback_method. Когда пункты программы начинаются с параметра get‒, необходимо прописать get_ex_callback. В других ситуациях разбираем JSON и пытаемся получить ключ t.
@bot.callback_query_handler(func=lambda call: True)
def iq_callback(query):
data = query.data
if data.startswith('get-'):
get_ex_callback(query)
else:
try:
if json.loads(data) == 'u':
edit_message_callback(query)
except ValueError:
pass
Если t равняется u, потребуется создать программу для метода edit_message_callback. Разберем эту процедуру по шагам:
- Загрузка актуальной информации о состоянии валютного рынка (exchange_now = pb.get_exchange(data).
- Написание нового сообщения через сериализатор с diff.
- Добавление подписи (get_edited_signature).
Если начальное сообщение не меняется, вызовем метод edit_message_text.
def edit_message_callback(query):
data = json.loads(query.data)
exchange_now = pb.get_exchange(data)
text = serialize_ex(
exchange_now,
get_exchange_diff(
get_ex_from_iq_data(data),
exchange_now
)
) + '\n' + get_edited_signature()
if query.message:
bot.edit_message_text(
text,
query.message.chat.id,
query.message.message_id,
reply_markup=get_update_keyboard(exchange_now),
parse_mode='HTML'
)
elif query.inline_message_id:
bot.edit_message_text(
text,
inline_message_id=query.inline_message_id,
reply_markup=get_update_keyboard(exchange_now),
parse_mode='HTML'
)
Пропишем метод get_ex_from_iq_data, чтобы разобрать JSON:
def get_ex_from_iq_data(exc_json):
return {
'buy': exc_json,
'sale': exc_json
}
Понадобится еще несколько методов: например, get_exchange_diff, который считывает старую и новую информацию о стоимости валют и выводит разницу.
def get_exchange_diff(last, now):
return {
'sale_diff': float("%.6f" % (float(now) - float(last))),
'buy_diff': float("%.6f" % (float(now) - float(last)))
}
Последний – get_edited_signature – показывает время последнего обновления курса.
def get_edited_signature():
return '<i>Updated ' + \
str(datetime.datetime.now(P_TIMEZONE).strftime('%H:%M:%S')) + \
' (' + TIMEZONE_COMMON_NAME + ')</i>'
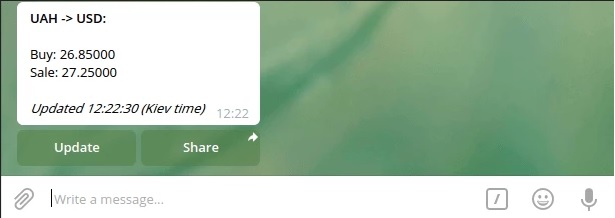
В результате обновленное сообщение от бота при стабильном курсе выглядит так:
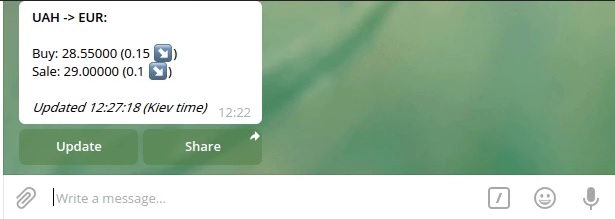
Когда курс меняется, различия между значениями отображаются в сообщении благодаря прописанным параметрам.
Недостатки с нашим ботом
Самая очевидная проблема с нашим ботом в том, что мы должны запустить сценарий Python вручную каждый раз, когда мы хотим взаимодействовать с ним. Также, как уже упоминалось ранее, мы всегда загружаем всю историю сообщений, которую предлагает Telegram. Это как неэффективно, так и ненадежный, как мы не хотим, чтобы не заплачали все историю сообщений, если мы хотим только одно сообщение, и потому что Telegram поддерживает только этот список обновлений в течение 24 часов. Другой вопрос заключается в том, что мы передаем наше сообщение как строку, но потому что это преобразуется в URL перед отправкой в Telegram, вы заметите, что некоторые неожиданные вещи происходят, если вы отправляете сообщения на бот со специальными символами (например, + Символ исчезнет из всех эховых сообщений). Наконец, бот бросает ошибку индекса, если мы стараемся запустить его, когда нет новых сообщений для получения.
Теперь мы обновим наш бот:
- Постоянно слушать новые сообщения и ответить на каждый.
- Подтвердите каждое сообщение, поскольку он получает его и сообщает Telegram не отправлять нам это сообщение снова.
- Используйте длительный опрос, чтобы мы не должны были сделать слишком много запросов.
- Правильно кодируйте наши сообщения для учета форматирования URL.
Как скачать и отправить стикер пользователю из Telegram бота
Думаю это будет интересный пример, сейчас мы научимся отправлять Стикеры из telegram бот на python3. Для того что бы отправить стикер из бота, нам нужно узнать ID нужного нам стикера. Сделать это просто, отправьте любой стикер боту «@StickerID_Bot» и он в ответ вернёт Вам ID файла.
Как отправить Стикер
@bot.message_handler(content_types=)
def text(message):
if message.text == ‘sticker’:
bot.send_sticker(message.chat.id, ‘CAADAgADsQADWQMDAAEJK1niI56hlhYE’)
|
1 |
@bot.message_handler(content_types=»text») def text(message) ifmessage.text==’sticker’ bot.send_sticker(message.chat.id,’CAADAgADsQADWQMDAAEJK1niI56hlhYE’) |
Если пользователь боту пришлёт слово «sticker» то в ответ мы отправим ему свой стикер. За место send_message вызывается метод send_sticker также передаётся id и за место текста отправляется ID стикера. Все просто — стикер отправлен))
Как получить Стикер (Скачать на локальную машину)
Давайте скачаем на локальную машину файл стикера, который прислал пользователь боту.
@bot.message_handler(content_types=)
def handle_docs_audio(message):
# Получим ID Стикера
sticker_id = message.sticker.file_id
# Нужно получить путь, где лежит файл стикера на Сервере Телеграмма
file_info = bot.get_file(sticker_id)
# Теперь формируем ссылку и скачивам файл
urllib.request.urlretrieve(f’http://api.telegram.org/file/bot{config.token}/{file_info.file_path}’, file_info.file_path)
|
1 |
@bot.message_handler(content_types=»sticker») def handle_docs_audio(message) # Получим ID Стикера sticker_id=message.sticker.file_id # Нужно получить путь, где лежит файл стикера на Сервере Телеграмма file_info=bot.get_file(sticker_id) # Теперь формируем ссылку и скачивам файл urllib.request.urlretrieve(f’http://api.telegram.org/file/bot{config.token}/{file_info.file_path}’,file_info.file_path) |
Собственно опять «message»! Пользователь отправляет нам стикер. Находим ID Стикера и отдаём его методу «get_file» что бы получить путь до файла на сервере телеграмма. А дальше скачаем файл в папку «stickers» которую нужно создать в том каталоге, где находится весь проект бота.
Взаимодействуя с нашим ботом через ваш веб-браузер
Мы можем контролировать наш бот, отправив HTTPS-запросы на телеграмму. Это означает, что самый простой способ взаимодействовать с нашим ботом через веб-браузер. Посещая разные URL-адреса, мы отправляем разные команды нашу бот. SimpleSt Command – это то, где мы получаем информацию о нашем боте. Посетите следующий URL в вашем браузере (подставляя токен бота, который вы получили раньше)
https://api.telegram.org/bot/getme
Первая часть URL указывает, что мы хотим общаться с Telegram API (API.TELEGRAMAM.ORG). Мы следуем это с Чтобы сказать, что мы хотим отправить команду нашему боту, и сразу после того, как мы добавим наш токен, чтобы определить, какой бот мы хотим отправить команду и доказать, что у нас есть. Наконец, мы указываем команду, которую мы хотим отправить ( ), которая в этом случае только что возвращает базовую информацию о нашем боте, используя JSON. Ответ должен выглядеть похоже на следующее:
{"ok":true,"result":{"id":248718785,"first_name":"To Do Bot","username":"exampletodo_bot"}}
Получение сообщений, отправленных на наш бот
Самый простой способ для нас для получения сообщений, отправленных на наш бот, проходит через вызов. Если вы посетите , вы получите ответ JSON всех новых сообщений, отправленных на ваш бот. Наш бот – совершенно новый и, вероятно, еще не получил никаких сообщений, поэтому, если вы сейчас посетите это, вы должны увидеть пустой ответ.
Telegram Bots не могут говорить с пользователями, пока пользователь сначала не инициирует разговор (это уменьшить спам). Для того, чтобы попробовать Звоните, мы сначала отправлю сообщение на наш бот из нашей собственной учетной записи Telegram. Посетить Чтобы открыть разговор с вашим ботом в веб-клиенте (или найти в любой из клиентов Telegram). Вы должны увидеть ваш бот, отображаемый с . кнопка в нижней части экрана. Нажмите эту кнопку, чтобы начать общаться со своим ботом. Отправьте свой бот короткое сообщение, например «Hello».
Теперь посетите URL снова, и вы должны увидеть ответ JSON, показывающую сообщения, которые получили ваш бот (включая один из при нажатии кнопки «Пуск»). Давайте посмотрим на пример этого и выделите данные импорта, которые мы будем писать код для извлечения в следующем разделе.
{"ok":true,"result":[{"update_id":625407400,
"message":{"message_id":1,"from":{"id":24860000,"first_name":"Gareth","last_name":"Dwyer (sixhobbits)","username":"sixhobbits"},"chat":{"id":24860000,"first_name":"Gareth","last_name":"Dwyer (sixhobbits)","username":"sixhobbits","type":"private"},"date":1478087433,"text":"\/start","entities":}},{"update_id":625407401,
"message":{"message_id":2,"from":{"id":24860000,"first_name":"Gareth","last_name":"Dwyer (sixhobbits)","username":"sixhobbits"},"chat":{"id":24860000,"first_name":"Gareth","last_name":"Dwyer (sixhobbits)","username":"sixhobbits","type":"private"},"date":1478087624,"text":"test"}}]}
Раздел JSON – список обновлений, которые мы еще не подтвердили (мы поговорим о том, как подтвердить обновления позже). В этом примере наш бот имеет два новых сообщения. Каждое сообщение содержит кучу данных о том, кто его отправил, какой чат он является частью, и содержимое сообщения. Две детали информации, на которой мы сосредоточимся на данный момент, – это идентификатор чата, который позволит нам отправить ответное сообщение и текст сообщения, который содержит текст сообщения. В следующем разделе мы увидим, как извлечь эти две части данных с помощью Python.
Отправка сообщения от нашего бота
Окончательный вызов API, который мы попробуем в нашем браузере, которое используется для отправки сообщения. Для этого нам нужен идентификатор чата для чата, где мы хотим отправить сообщение. Есть куча разных идентификаторов в ответе JSON от Позвоните, так что убедитесь, что вы получите правильный. Это поле, которое находится внутри поле (24860000 в примере выше, но ваши будут разные). Как только у вас есть этот идентификатор, посетите следующий URL в вашем браузере, подставляя для вашего идентификатора чата.
https://api.telegram.org/bot/sendMessage?chat_id=&text=TestReply
После того, как вы посетили этот URL, вы должны увидеть сообщение от вашего бота, отправленного на ваш, который говорит «Testreply».
Теперь, когда мы знаем, как отправлять и получать сообщения, используя API Telegram, мы можем перейти с автоматическим использованием этого процесса, написав несколько логики в Python.
Готовим программу и отправляем её на сервер
Единственное, что нужно добавить в наш код телеграм-бота, — специальную команду интерпретатору, чтобы он знал, как работать с нашим файлом. Но перед этим нужно проверить, какая версия Python на нём установлена.
Чтобы это узнать, соединимся с сервером по протоколу SSH и спросим у него напрямую. Для этого используем программу Putty, а настройки подключения возьмём в личном кабинете хостинга:
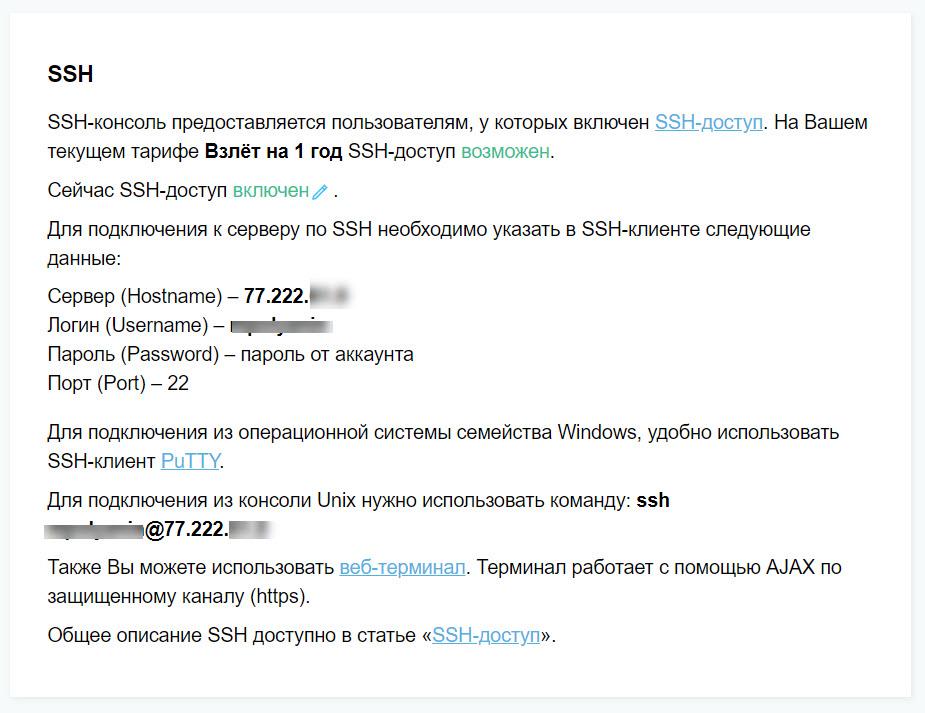 Этих данных достаточно, чтобы управлять сервером по SSH.
Этих данных достаточно, чтобы управлять сервером по SSH.
Вставляем их в Putty и подключаемся. Помните, что для безопасности во время ввода пароля курсор стоит на месте, чтобы никто не смог выяснить, сколько символов вы набираете. Когда подключились, вводим команду python3.3 -V — она покажет, есть ли на сервере поддержка этой версии Python:
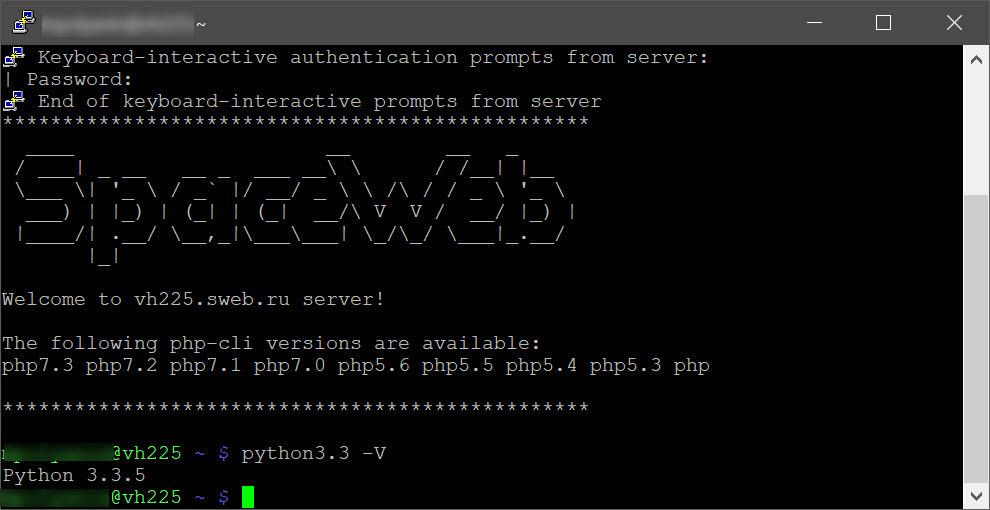 Сервер говорит, что у него установлена версия Python 3.3.5 — нам этого хватит. Теперь добавляем в самое начало нашего файла с программой такую строчку:
Сервер говорит, что у него установлена версия Python 3.3.5 — нам этого хватит. Теперь добавляем в самое начало нашего файла с программой такую строчку:
В статье о том, как опубликовать сайт в интернете, мы рассказывали, как залить файлы на сервер. Это умение нам сейчас пригодится: сохраняем нашу программу с гороскопом как файл с расширением .py и отправляем его на сервер в папку cgi-bin (то, что лежит в этой папке, никто не увидит):
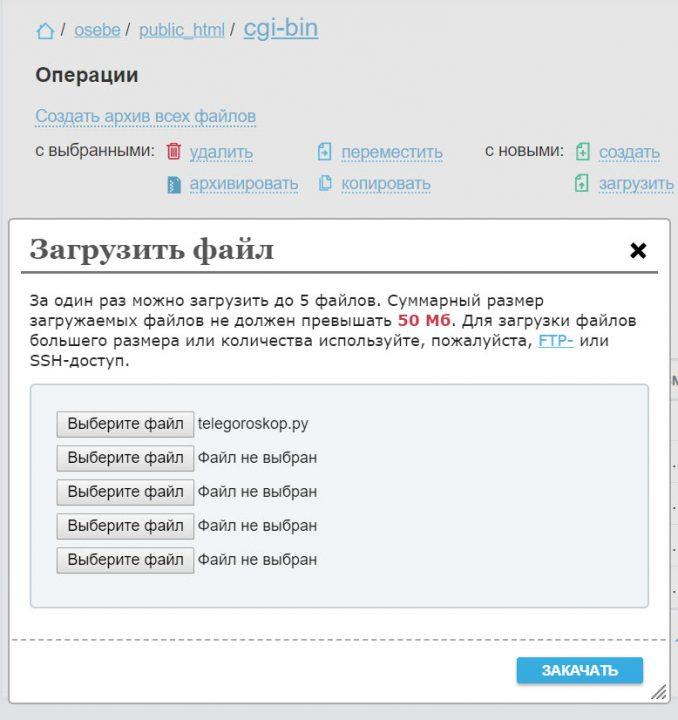
Создаём проект
Для начала создадим проект с такой структурой:
В будут находиться хендлеры — обработчики событий.
В будем хранить секретные данные. Давайте сразу его заполним:
Конечно, вы можете хранить эти данные любым удобным для вас способом. Но я буду далее использовать файл config.
Итак, давайте приступим к заполнению . Главное, что нам нужно из библиотеки telethon — класс . Именно с его помощью мы сможем авторизоваться через бота.
Позже нам понадобится хранить информацию о боте (его id, юзернейм и так далее). Поэтому давайте сразу сделаем свой собственный класс, который будет наследоваться от TelegramClient:
Пока что мы только создали объект бота и ничего больше. Чуть позже мы реализуем авторизацию бота с помощью токена. (Указанная строка будет названием файла сессии: он создастся после авторизации.)
Зададим для бота — режим разметки по умолчанию. Он будет использоваться при отправке и получении сообщений с разметкой (жирный текст, курсив, ссылки и так далее). Выберем HTML.
И заодно настроим логгинг:
Когда объект bot уже создан, нам нужно зарегистрировать все хендлеры: для этого импортируем app.handlers (сейчас в том файле ничего нет).
Теперь напишем функцию, которая будет авторизовывать бота и обрабатывать его апдейты.
И, наконец, функцию run, которая запускает нашу асинхронную функцию start:
Переходим к хендлерам.
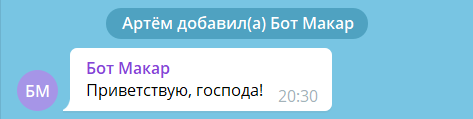
Как я уже говорил, в handlers.py мы будем обрабатывать события. Давайте будем ловить события о добавлении бота в группу.
Как это сделать? Мы должны ловить именно системные сообщения (это сообщения вида «добавил пользователя в группу», «изменил название группы», «закрепил сообщения» и так далее). Если это системное сообщение:а) было в группе,б) говорит о том, что какой-то пользователь добавил другого пользователя,в) относится именно к боту,то это значит, что нашего бота добавили в группу. Пусть тогда бот напишет в эту группу: «Приветствую, господа!»
Чтобы использовать событие с новыми системными сообщениями, нам понадобится класс telethon.events.ChatAction.
Всё это будет выглядеть так:
Декоратором мы привязываем нашу функцию к нужному событию. Функция принимает объект типа «событие о системном сообщении». Если условия выполняются, то отправляется сообщение.
Теперь последний штрих — файл В нём мы просто импортируем и запускаем нашу функцию run:
Готово! Бота можно запускать.
Где взять данные для обучения
Чтобы получить данные для обучения бота, можно исследовать достаточно много разных ресурсов. Например, есть сборник диалогов из фильмов от Корнеллского университета (Cornell movie dialogue corpus) — он пользуется большой популярностью. Есть также и множество других источников, но нам бы хотелось найти что-то более сырое, что ли. Что-то менее изысканное, что-то с характером. Естественно, это сразу нас ведет на Reddit!
Сначала нам казалось, что мы сможем использовать Python Reddit API Wrapper, но ограничения, накладываемые Reddit на сканирование, не самые удобные. Чтобы собрать большие объемы данных, вам придется нарушить некоторые правила. Вместо этого мы нашли дамп данных из 1,7 миллиарда комментариев на Reddit. Что ж, это должно сработать!
Reddit имеет древовидную структуру в отличие от ряда других форумов, где все линейно. Родительские комментарии линейны, но ответы на них разветвляются. На всякий случай, если кто-то с этим незнаком:
Структура, которая нам нужна для глубокого обучения, это вход-выход. Так что нам нужно получить что-то большее, например пары комментарий-ответ. В приведенном выше примере мы могли бы использовать следующие пары комментарий-ответ:
Таким образом, нам нужно взять этот дамп Reddit и создать такие пары. Следующее, что нам нужно учитывать, это то, что у нас, вероятно, должен быть только 1 ответ на комментарий. Несмотря на то, что на многие отдельные комментарии может приходиться много ответов, на самом деле нам стоит остановиться на одном.
Мы можем просто взять первый комментарий, либо выбрать лучший — набравший наибольшее количество голосов. Подробнее на этом мы остановимся позже. Наша первая задача — получить данные. Если у вас есть проблемы с хранением данных, вы можете взять данные только за один месяц, за январь 2015 года. В противном случае вы можете скачать весь дамп целиком:
Мы качали этот торрент два раза, но в зависимости от количества сидов и пиров время загрузки может сильно варьироваться.
Наконец, вы также можете получить доступ к данным через Google BigQuery: Google BigQuery of all Reddit comments. Таблицы BigQuery со временем обновляются, а торрент — нет, так что это тоже хороший вариант.
Мы будем использовать торрент, так как он абсолютно бесплатен, и если вы хотите в точности следовать инструкциям, он вам понадобится. Но никогда не надо стесняться идти своим путем, поэтому при желании вы всегда можете выбрать и другие варианты.
Поскольку загрузка данных может занять значительное время, мы пока прервемся на этом. А после загрузки данных перейдем к следующей статье. Для работы с нашими статьями вам вполне будет достаточно скачать только один файл 2015-01, все 1.7 миллиардов комментариев загружать совсем не обязательно. Комментариев за один месяц должно хватить.
Следующая статья — Чат-бот на Python (Deep Learning + TensorFlow). Часть II.
Как работает чат-бот?
Существует два типа ботов: работающие по правилам и самообучающиеся.
- Бот первого типа отвечает на вопросы, основываясь на некоторых правилах, которым он обучен. Правила могут быть как простыми, так и очень сложными. Боты могут обрабатывать простые запросы, но не справлятся со сложными.
- Самообучающиеся боты создаются с использованием основанных на машинном обучении методов и определенно более эффективны, чем боты первого типа. Самообучающиеся боты бывают двух типов: поисковые и генеративные.
В поисковых ботах используются эвристические методы для выбора ответа из библиотеки предопределенных реплик. Такие чат-боты используют текст сообщения и контекст диалога для выбора ответа из предопределенного списка. Контекст включает в себя текущее положение в древе диалога, все предыдущие сообщения и сохраненные ранее переменные (например, имя пользователя). Эвристика для выбора ответа может быть спроектирована по-разному: от условной логики «или-или» до машинных классификаторов.
Генеративные боты могут самостоятельно создавать ответы и не всегда отвечают одним из предопределенных вариантов. Это делает ихинтеллектуальными, так как такие боты изучают каждое слово в запросе и генерируют ответ.
В этой статье мы научимся писать код простых поисковых чат-ботов на основе библиотеки NLTK.
Telebot и сила python
Мне всегда казалось, что создавать бота — это не так просто. Честно говоря, давно хотел попробовать, но то ли не хватало времени (думал, что это займет не один вечер), то ли не мог выбрать технологию (как-то смотрел туториал для c#), ну а скорее всего было просто лень. Но тут мне понадобилось это для работы, так что я больше не смел откладывать.
Сила python заключается в его популярности. А, как следствие, в появлении огромного количества сторонних библиотек практически под все нужды. Именно это сделало возможным написание примитивного бота (который просто отвечает однотипно на сообщения) в 6 (ШЕСТЬ!) строчек кода. А именно:
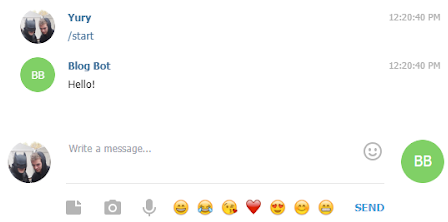 Первое сообщение
Первое сообщение
На самом деле бот будет отвечать только на команду /start, но для начала неплохо. Здесь все довольно просто: в первой строчке импортируется библиотека telebot (для ее работы необходимо установить пакет pyTelegramBotAPI командой (НЕ !), далее создаем объекта бот, используя токен, который нам прислал BotFather. Третья строчка проверяет, что присылают пользователи (в данном случае это только команда “/start”), и, если проверка пройдена, то бот отправляет ответ с текстом “Hello!”. Последняя строчка, наверное, самая сложная для понимания, и в следующих разделах я ее подробно разберу. Сейчас же я только скажу о ее предназначении — она заставляет бота работать, то есть «реагировать» на полученные сообщения.
Как работают Instagram боты
Как сценарий автоматизации поможет получить нам больше подписчиков и лайков? Прежде чем ответить на этот вопрос, подумайте о том, как реальные люди приобретают большее число своих подписчиков и лайков.
Они делают это, будучи постоянно активными на целевой платформе. Они часто публикуют посты, подписываются на обновления аккаунтов других людей, а также ставят лайки и оставляют комментарии к постам других людей. И боты работают точно так же: они подписываются, ставят лайки и самостоятельно добавляют комментарии в соответствии с установленными вами критериями.
Чем оптимальнее определены эти критерии, тем лучше будут результаты. Вы должны убедиться, что подписаны на нужные группы, так как в этом случае люди, с которыми ваш бот взаимодействует в Instagram, с большей вероятностью будут взаимодействовать с вашим контентом.
Например, если вы продаете женскую одежду на Instagram, то можете указать вашему боту преимущественно ставить лайки комментариям, а также подписываться на группы женщин, чьи профили и посты включают хештеги , или . Это повысит вероятность того, что нужная вам целевая аудитория заметит ваш профиль, начнет подписываться на него, читать и обсуждать вашими публикации.
Как же это работает с технической точки зрения? Для этих целей нам совершенно не подходит Instagram Developer API, так как его возможности весьма ограничены.
И так приступим к непосредственно автоматизации работы браузера. Она будет осуществляться следующим образом:
- Вы предоставите ей все свои полномочия (логин и пароль аккаунта).
- Устанавливаете критерии поведения бота для случаев, на какие паблики подписываться, какие комментарии оставлять и каким типам постов ставить лайки.
- Затем ваш бот открывает браузер, вводит в адресной строке , входит в профиль с вашими учетными данными, и начинает делать то, что вы ему указали.
Далее мы создадим первоначальную версию своего Instagram бота, которая будет автоматически входить в ваш профиль
Обратите внимание, пока мы не будете использовать библиотеку InstaPy
Подключаем библиотеку и получаем сообщения
Чтобы программа на Python умела управлять Телеграм-ботами, нужно в самое начало кода добавить строки:
Единственное, о чём нужно не забыть — заменить слово «токен» на настоящий токен, который дал нам @BotFather. Открываем программу гороскопа и добавляем.
Теперь научим бота реагировать на слово «Привет». Для этого добавим после строчек с импортом новый метод и сразу пропишем в нём реакцию на нужное слово. Если не знаете, что такое метод и зачем он нужен, — читайте статью про ООП.
И последнее, что нам осталось сделать до запуска, — добавить после метода такую строчку:
Она скажет программе, чтобы она непрерывно спрашивала у бота, не пришли ли ему какие-то новые сообщения. Запускаем программу и проверяем, как работает наш бот.
Бот отвечает именно так, как мы запрограммировали. Класс.Такая ошибка во время запуска программы означает, что компьютер не может соединиться с сервером telegram.org, потому что его блокирует Роскомнадзор. Что делать? Сложно сказать. Если бы вы жили в другой стране, этой проблемы бы не было. Ещё можно использовать какие-то средства, которые направляют ваш трафик через другую страну, но рассказ об этих средствах является в России преступлением, поэтому тут мы вам ничего не можем подсказать.
Соединение
Чем больше я работал с библиотекой telebot, тем больше она мне нравилась. Хотелось бы, используя приложение на flask’e, не терять эту возможность. Но как это сделать? Во-первых, мы можем вместо нашей функции send_message использовать готовую из библиотеки. Это будет выглядеть так:
Но, если присмотреться, можно заметить, что мы потеряли часть функционала, а именно @bot.message_handler — декораторы, которые отслеживают тип введенного боту сообщения (картинка, документ, текст, команда и т. д.). Получается, что если мы используем в качестве сервера наше flask приложение, то мы теряем некоторый функционал библиотеки telebot. Если же мы используем bot.polling(), то мы не можем обращаться к серверу “со стороны”. Конечно, хотелось бы как-то все соединить без потерь. Для этого я нашел немного костыльный способ, однако рабочий:
Здесь мы пользуемся методом set_webhook, аналогично тому, как мы делали это ранее через postman, а на пустом роуте прописываем «немного магии», чтобы успешно получать обновления бота. Конечно, это не очень хороший способ, и в дальнейшем лучше самостоятельно прописывать функционал для обработки входящих сообщений. Но для начала, я считаю, это лучшее решение.
Заключение
Хотя наш примитивный бот едва ли обладает когнитивными навыками, это был неплохой способ разобраться с NLP и узнать о работе чат-ботов. «ROBO», по крайней мере, отвечает на запросы пользователя. Он, конечно, не обманет ваших друзей, и для коммерческой системы вы захотите рассмотреть одну из существующих бот-платформ или фреймворки, но этот пример поможет вам продумать архитектуру бота.
Интересные статьи:
- Как создать собственную нейронную сеть с нуля на языке Python
- Word2Vec: как работать с векторными представлениями слов
- Как применять теорему Байеса для решения реальных задач